


Deploying machine learning models at scale can be challenging. From managing infrastructure to handling varying workloads, the complexities can slow down progress. Fortunately, AWS SageMaker simplifies this process with its robust suite of tools and features, empowering data scientists and developers to focus on innovation instead of infrastructure.
Why Choose SageMaker for Deployment?
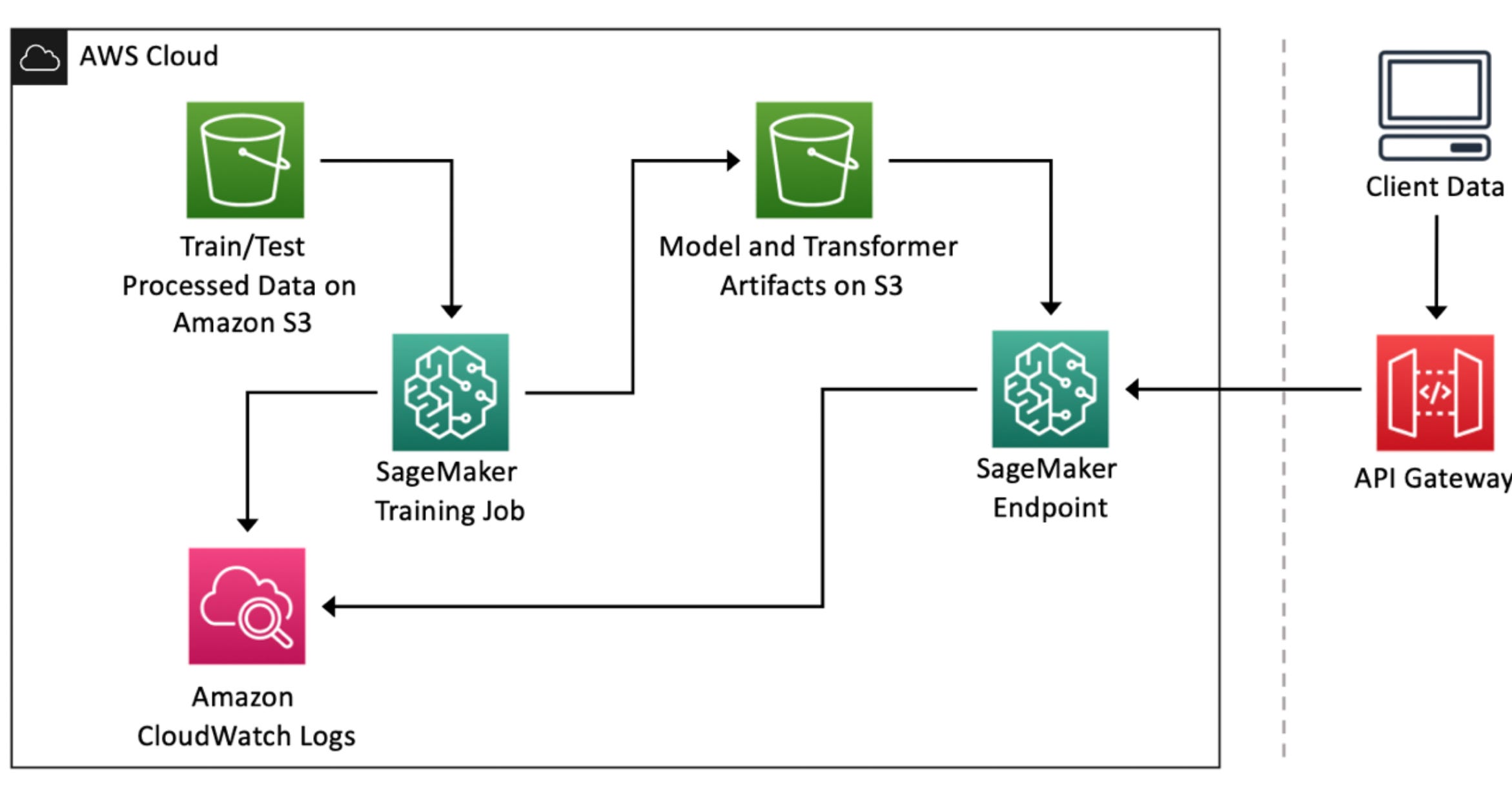
AWS SageMaker is a fully managed service designed to streamline every step of the machine learning lifecycle. Whether you're preparing data, training models, or deploying and monitoring them, SageMaker has you covered. Here are its key advantages for deployment:
Key Benefits
Ease of Use: Abstracts away infrastructure complexities, allowing you to focus on building and deploying models.
Scalability: Automatically scales deployments to meet varying workloads, from low-latency requirements to large-scale batch processing.
Flexibility: Supports diverse deployment options, including real-time endpoints, batch transformations, asynchronous inference, and serverless inference.
Integration: Seamlessly integrates with AWS services like S3, Lambda, and CloudWatch, enabling a smooth workflow.
Deployment Options in SageMaker
AWS SageMaker offers a range of deployment strategies tailored to different use cases. Let’s explore each:
1. Real-Time Endpoints
Best For: Low-latency applications like fraud detection, recommendation systems, or chatbots. SageMaker hosts your model behind an HTTPS endpoint, enabling real-time predictions. This is ideal for use cases requiring instant responses.
2. Batch Transformations
Best For: Offline processing of large datasets, such as generating predictions for analytics or reports. Batch transformations allow you to run predictions on datasets stored in S3, processing them in bulk.
3. Asynchronous Inference
Best For: Long-running tasks like video processing or complex simulations. Asynchronous endpoints let you queue requests and retrieve results when ready, making them perfect for workloads that don’t need immediate responses.
4. Serverless Inference
Best For: Sporadic or unpredictable workloads. Serverless inference automatically provisions and scales resources, ensuring cost efficiency while meeting demand.
Below are example codes you can use for deploying models on AWS SageMaker via various deployment options. These examples leverage SageMaker's built-in capabilities, so there’s no need for custom code or logic to handle endpoints—SageMaker manages this directly. In my next post, I’ll cover how to port locally trained models to SageMaker, which will involve writing custom endpoint processing logic.
Deploying a Model with AWS SageMaker: Real-Time Endpoint
Below is an example of deploying a model to a real-time endpoint using SageMaker:
import boto3
import sagemaker
from sagemaker import get_execution_role
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.serializers import JSONSerializer
from sagemaker.deserializers import JSONDeserializer
# Initialize SageMaker session and role
sagemaker_session = sagemaker.Session()
role = get_execution_role()
# Define the S3 path to your trained model artifacts
model_artifacts = "s3://your-bucket-name/path-to-model-artifacts"
# Define the Docker container image for inference
image_uri = "123456789012.dkr.ecr.us-west-2.amazonaws.com/my-inference-image:latest"
# Create a SageMaker Model
model = Model(
model_data=model_artifacts,
image_uri=image_uri,
role=role,
sagemaker_session=sagemaker_session
)
# Deploy the model to a real-time endpoint
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.m5.large",
endpoint_name="my-endpoint"
)
# Configure the predictor
predictor.serializer = JSONSerializer()
predictor.deserializer = JSONDeserializer()
# Example: Make a prediction
data = {
"feature1": 0.5,
"feature2": 1.2,
"feature3": 3.7
}
response = predictor.predict(data)
print("Prediction:", response)
# Clean up: Delete the endpoint (optional)
# predictor.delete_endpoint()Explanation of the Code
Initialize SageMaker Session: Create a session and retrieve the IAM role.
Model Artifacts: Specify the S3 location of the trained model.
Docker Image: Use an appropriate image for your framework (e.g., TensorFlow, PyTorch).
Deploy the Model: Create a real-time endpoint with
model.deploy().Make Predictions: Send input data to the endpoint and retrieve predictions.
Clean Up: Optionally delete the endpoint to avoid unnecessary costs.
Batch Transformations: Processing Data at Scale
For bulk processing of datasets, you can use SageMaker's batch transformation feature:
from sagemaker.transformer import Transformer
# Define S3 paths
input_data_path = "s3://your-bucket-name/input-data/"
output_data_path = "s3://your-bucket-name/output/"
# Create a Transformer object
transformer = Transformer(
model_name="your-model-name",
instance_count=1,
instance_type="ml.m5.large",
output_path=output_data_path,
strategy="SingleRecord"
)
# Start the batch transformation job
transformer.transform(
data=input_data_path,
data_type="S3Prefix",
content_type="text/csv",
split_type="Line"
)
# Wait for job completion
transformer.wait()
print("Batch Transform job completed! Predictions saved to:", output_data_path)Explanation of the Code
Input and Output Paths: Define S3 locations for input data and predictions.
Transformer Configuration: Set up the batch transformation with parameters like instance count and type.
Start the Job: Use
transform()to start processing data.Output: Predictions are saved to the specified S3 path.
Asynchronous Inference: Handling Long-Running Tasks
For tasks requiring extended processing times, AWS SageMaker’s Asynchronous Inference is ideal. This feature allows you to submit requests, queue them for processing, and retrieve results once they’re ready:
import boto3
import sagemaker
from sagemaker.model import Model
# Define S3 paths for input and output
input_data_path = "s3://your-bucket-name/input-data/"
output_data_path = "s3://your-bucket-name/output-data/"
# Initialize SageMaker session
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
# Define model artifacts and image URI
model_artifacts = "s3://your-bucket-name/path-to-model-artifacts"
image_uri = "123456789012.dkr.ecr.us-west-2.amazonaws.com/my-inference-image:latest"
# Create the model
model = Model(
model_data=model_artifacts,
image_uri=image_uri,
role=role,
sagemaker_session=sagemaker_session
)
# Deploy to an asynchronous endpoint
predictor = model.deploy(
instance_type="ml.m5.large",
initial_instance_count=1,
async_inference_config={
"OutputConfig": {
"S3OutputPath": output_data_path, # Path to save predictions
"NotificationConfig": {
"SuccessTopic": "arn:aws:sns:region:account-id:SuccessTopic", # Optional SNS topic for success
"ErrorTopic": "arn:aws:sns:region:account-id:ErrorTopic" # Optional SNS topic for errors
}
}
}
)
# Submit an asynchronous request
client = boto3.client('sagemaker-runtime')
response = client.invoke_endpoint_async(
EndpointName=predictor.endpoint_name,
InputLocation=f"{input_data_path}/input-file.json"
)
print("Asynchronous inference request submitted!")
print("Predictions will be saved to:", output_data_path)
Explanation of the Code
Input and Output Paths: Specify S3 locations for input data and predictions.
Async Configuration: Set
async_inference_configto define S3 output paths and optional SNS notifications.Submit Request: Use
invoke_endpoint_asyncto queue the request.Result Storage: Outputs are stored in the specified S3 path.
Serverless Inference: Cost-Efficient and Flexible
For sporadic workloads, SageMaker Serverless Inference is a cost-effective choice. It provisions and scales resources dynamically, ensuring you only pay for what you use”
import boto3
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
from sagemaker.model import Model
# Define S3 path to model artifacts
model_artifacts = "s3://your-bucket-name/path-to-model-artifacts"
image_uri = "123456789012.dkr.ecr.us-west-2.amazonaws.com/my-inference-image:latest"
# Initialize SageMaker session
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
# Create the model
model = Model(
model_data=model_artifacts,
image_uri=image_uri,
role=role,
sagemaker_session=sagemaker_session
)
# Define Serverless Inference Configuration
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=2048, # Memory allocation (e.g., 2048 MB)
max_concurrency=5 # Maximum concurrent invocations
)
# Deploy to a serverless endpoint
predictor = model.deploy(
serverless_inference_config=serverless_config,
endpoint_name="serverless-endpoint"
)
# Make a prediction
data = {
"feature1": 0.5,
"feature2": 1.2,
"feature3": 3.7
}
response = predictor.predict(data)
print("Serverless Prediction:", response)
Explanation of the Code
Model Creation: Specify S3 model artifacts and a Docker image URI.
Serverless Configuration: Define memory size and concurrency settings using
ServerlessInferenceConfig.Deploy the Endpoint: Use
model.deploy()withserverless_inference_config.Predict: Send data to the serverless endpoint and retrieve predictions.
Conclusion
AWS SageMaker offers a versatile and powerful platform for deploying machine learning models, catering to diverse use cases with options like real time, batch transformations, asynchronous inference, and serverless inference. Whether you’re handling bulk data processing, long-running tasks, or sporadic real-time predictions, SageMaker provides the tools to simplify infrastructure management, scale effortlessly, and optimize costs. By leveraging these capabilities, you can focus on delivering insights and innovation while SageMaker takes care of the heavy lifting.