


Language Models Overview
Prediction Task: Language models predict the likelihood of the next word in a sequence.
Example: Given "The most famous city in the US is...", the model might predict "New York" or "Los Angeles" with high probability.
Traditional Models: RNNs
Recurrent Neural Networks (RNNs): Process input sequences one step at a time.
LSTMs and GRUs: Common RNN architectures used for sequence tasks.
Challenges: Slow and hard to parallelize, making them computationally intensive.
Transformers: The Modern Approach
Self-Attention Mechanism: Allows parallel processing of sequences, improving speed and handling of long-term dependencies.
Advantages: Faster to train and better at managing long sequences compared to RNNs.
Limitations: Self-attention is quadratic in cost, limiting the context length for very long sequences.
Transformers are now the preferred model for sequence-based tasks like translation, text summarization, and classification. This paper explores both early and advanced transformer models.
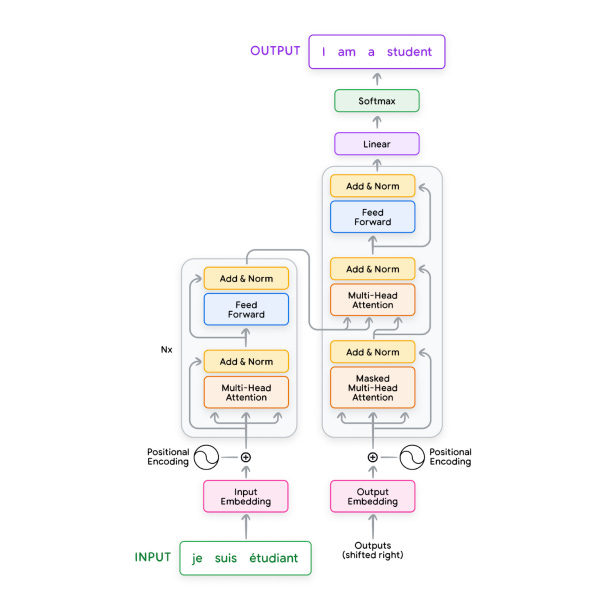
Transformer Architecture Overview
Development: The transformer architecture was created by Google in 2017 for translation tasks.
Sequence-to-Sequence Model: Designed to transform sequences from one domain to another, such as translating from French to English.
Encoder-Decoder Structure:
Encoder: Converts input text (e.g., a French sentence) into a meaningful representation.
Decoder: Uses this representation to generate output text (e.g., an English sentence) autoregressively.
Transformer Layers
Layer Composition: The transformer consists of multiple layers, each performing specific transformations on the data.
Example Layers: Include Multi-Head Attention, Add & Norm, Feed-Forward, Linear, and Softmax.
Layer Types:
Input Layer: Where raw data enters, with input embeddings representing the input tokens (e.g., source language words).
Hidden Layers: Perform intermediate transformations, such as Multi-Head Attention, where much of the model's processing takes place.
Output Layer: Produces the final result using layers like Softmax, outputting the predicted tokens (e.g., target language words in translation tasks).
Example: French-to-English Translation
Translation Process:
Input: The French sentence is fed into the transformer via input embeddings.
Encoding and Decoding: The encoder processes the input, and the decoder uses this encoded information to output an English translation.
Detailed Layer Breakdown: Each component—such as Multi-Head Attention and Feed-Forward—contributes to the transformation of input to output, illustrated in Figure 1.
This example demonstrates the step-by-step functioning of each layer in the transformer when handling tasks like translation.
Input Preparation and Embedding in Transformers
To process language inputs, transformers convert sentences into token-based representations that can be understood by the model. This involves several key steps:
Input Embeddings: High-dimensional vectors that capture the meaning of each token in the sentence, fed into the transformer for processing.
Steps to Generate Input Embeddings:
Normalization (Optional): Standardizes text by removing extra whitespace, accents, etc., for consistency.
Tokenization: Splits the sentence into words or subwords and assigns each a token ID based on a vocabulary.
Embedding: Maps each token ID to a high-dimensional vector (input embedding), typically through a lookup table, which can be learned during training.
Positional Encoding: Adds positional information to each token’s embedding, enabling the transformer to understand the order of words in the sequence.
Multi-Head Attention in Transformers
After converting tokens into embedding vectors, these embeddings are fed into the multi-head attention module, a core component in transformers.
Self-Attention Mechanism: Allows the model to focus on specific parts of the input sequence that are most relevant to the task.
Capturing Long-Range Dependencies: Multi-head attention effectively captures relationships across the sequence, enabling better context understanding compared to traditional RNNs.
Understanding Self-Attention
Self-attention enables the model to identify relationships between words within a sentence, helping it understand context better. For instance, in the sentence “The tiger jumped out of a tree to get a drink because it was thirsty,” self-attention can connect "the tiger" and "it" as referring to the same object.
Steps in Self-Attention:
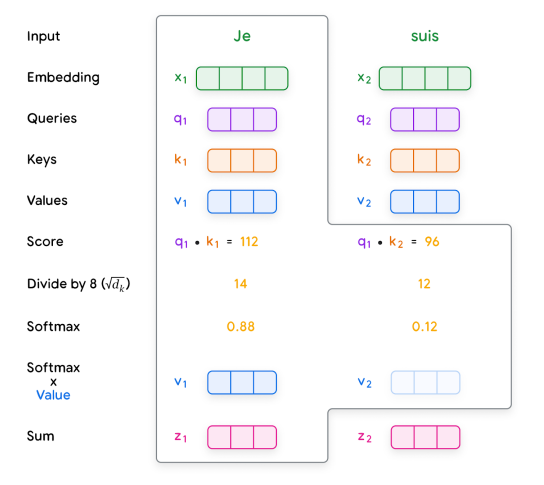
Creating Queries, Keys, and Values:
Each input embedding is multiplied by learned weight matrices to generate query (Q), key (K), and value (V) vectors, representing each word.
Query: Helps the model determine relevant words in the sequence.
Key: Acts as a label to identify how a word relates to others.
Value: Holds the actual content information of the word.
Calculating Scores:
The model calculates scores by taking the dot product of each word’s query vector with the key vectors of all words, determining how much each word should "attend" to others.
Normalization:
Scores are divided by the square root of the key vector dimension for stability, then passed through a softmax function to produce attention weights, indicating the strength of connection between words.
Weighted Values:
Each value vector is multiplied by its attention weight, and results are summed to create a context-aware representation for each word.
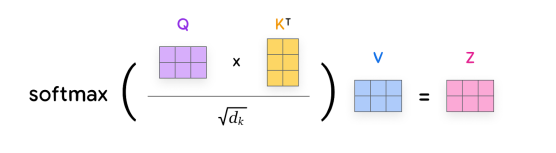
In practice, these steps are computed simultaneously by stacking all tokens' query, key, and value vectors into matrices (Q, K, V) and performing matrix multiplication, as shown above
Multi-Head Attention: Power in Diversity
Multi-head attention strengthens the model’s ability to understand complex language by using multiple sets of Q, K, V weight matrices in parallel.
Parallel Heads: Each "head" processes the input differently, allowing the model to focus on various aspects of word relationships.
Concatenation and Transformation: Outputs from each head are concatenated and linearly transformed to form a richer representation of the input sequence.
Benefits:
Enhanced Understanding: Multi-head attention improves the model’s capacity to capture complex language patterns and long-range dependencies.
Applications: This capability is essential for nuanced language tasks such as machine translation, text summarization, and question-answering.
Multiple Interpretations: By considering diverse interpretations of the input, multi-head attention boosts the model's overall performance on complex language tasks.
Layer Normalization and Residual Connections in Transformers
Each transformer layer, composed of a multi-head attention module and a feed-forward layer, includes layer normalization and residual connections, represented by the Add and Norm layer.
Layer Normalization:
Purpose: Computes the mean and variance of activations in a layer to normalize them.
Benefits: Reduces covariate shift and improves gradient flow, leading to faster convergence and better overall performance.
Residual Connections:
Function: Propagates inputs directly to the output of one or more layers, making optimization easier.
Advantages: Helps prevent vanishing and exploding gradients, facilitating stable and efficient learning.
The Add and Norm layer is applied to both the multi-head attention and feed-forward layers, ensuring smoother training and improved model stability.
Feedforward Layer in Transformers
After the multi-head attention module and the first Add and Norm layer, the data passes through the feedforward layer in each transformer block.
Position-Wise Transformation: The feedforward layer applies transformations independently to each position in the sequence, enhancing the model’s non-linear capabilities.
Structure:
Consists of two linear transformations with a non-linear activation function (e.g., ReLU or GELU) in between.
Adds complexity and representational power to the model, enabling it to capture more intricate patterns in the data.
Additional Add and Norm Step: After the feedforward layer, the data undergoes another Add and Norm operation, contributing to model stability and performance in deep transformer architectures.
Transformer Architecture: Encoder and Decoder Modules
The original transformer relies on both encoder and decoder modules, each consisting of layers with multi-head self-attention, feedforward networks, normalization layers, and residual connections.
Encoder Module
Purpose: Processes the input sequence into a continuous representation that holds contextual information for each token.
Steps:
Input Preparation: The sequence is normalized, tokenized, and converted into embeddings, with positional encodings added to retain sequence order.
Self-Attention: Allows each token to attend to any other token in the sequence, capturing contextual relationships.
Output: Produces a series of embedding vectors ZZZ representing the contextualized input sequence.
Decoder Module
Purpose: Generates an output sequence based on the encoder’s output ZZZ, processing tokens in an auto-regressive manner.
Steps:
Masked Self-Attention: Ensures each token can only attend to previous tokens in the output, preserving the sequence generation order.
Encoder-Decoder Cross-Attention: Allows the decoder to focus on relevant parts of the input sequence by using the encoder's contextual embeddings.
Output Generation: Continues token-by-token until reaching an end-of-sequence token, completing the output sequence.
Decoder-Only Architecture in Recent LLMs
Streamlined Design: Recent language models often use a decoder-only architecture, omitting the encoder.
Process: The input undergoes embedding and positional encoding, then passes through the decoder, which generates the output sequence using masked self-attention.
Benefits: Simplifies the model for tasks where encoding and decoding can be effectively merged, focusing on direct sequence generation.