

From NLTK to LangGraph: How LangChain’s Limitations Paved the Way for Graph-Based AI
A Chronological Breakdown of Frameworks Leading to LangGraph, the Next-Gen Solution for Stateful, Multi-Agent LLM Applications

Here is the first of many in the series of Graph RAG and graph-based AI applications. My overall goal for this series is to explore how graph-based approaches, particularly the Graph RAG methodology, can revolutionize the way we build and deploy agentic AI systems by leveraging interconnected data structures and hierarchical relationships. With all the excitement around AI and agentic frameworks, LangGraph stands out as a strong and reliable implementation framework for creating powerful, graph-based agentic applications, which I am planning to dive deeper into and discuss in this post.
Before diving into LangGraph, let me briefly introduce other tools available for integrating large language models (LLMs). Before LangGraph emerged, frameworks and methods focused on modular designs, retrieval systems, or task-specific optimizations for NLP and conversational AI. However, they often lacked the comprehensive integration and flexibility that LangGraph now offers.
The following is a breakdown of popular frameworks, organized chronologically (though there may be some overlap or conflicts in timelines):
Traditional NLP Frameworks (Pre-Large Langugage Models)
The traditional frameworks focused on text processing and statistical approaches before deep learning boom. Some of the popular traditional frameworks are as follows:
NLTK (Natural Language Toolkit):
Early library for text preprocessing, tokenization, stemming, and more. This was a great framework at the time but had limitations when it comes to scalability and no seamless integration with machine learning models.
SpaCy:
NLP library for named entity recognition, dependency parsing, and tokenization. This framework was not designed for conversational systems.
Standford CoreNLP:
Comprehensive Java-based NLP tools for linguistic analysis and feature extraction. Some limitations include not able to scale to modern neural network applications.
Deep Learning Frameworks (Pre-LangGraph)
Deep Learning boom led to lots of advancement in NLP space, the major one include the advent of transformers which eventually led to Large Language models. Some of the popular deep learning frameworks are as follows:
AllenNLP (2017):
A deep learning framework tailored for NLP, offering modular pipelines for tasks like sentiment analysis and machine comprehension. This was a good step towards the democratization and standardization of NLP . However this did not support large scale retrieval tasks.
Open AI GPT Models (2018+)
Open AI GPT models are foundation for conversational AI that focused primarily on unstructured texts. For more specific use-cases or custom solutions, it required knowledge enhanced tasks.
Hugging Face Transformers (2019):
This pretty much revolutionized NLP with pre-trained transformer models like BERT, GPT, and T5. While these were very powerful models, they focused on single-turn tasks and lacked structured data integration.
Graph-Specific Libraries
While the advancements in NLP was ongoing, there were various graph based tools that were also making leaps; although some developed with no specific usecase with NLP in mind. Here are few popular inovation in this space:
NetworkX (2005):
Open-source Python library for creating and analyzing graph structures. This tool was more general purpose with no focus on NLP.
Neo4j (2010):
A graph database designed for scalable querying and manipulation of graph data, widely used for knowledge graph applications. Again, more general purpose but this could support external integration for NL and deep learning.
DGL (Deep Graph Library) and PyTorch Geometric (2018):
Popular frameworks for implementing graph neural networks (GNNs) and working with graph data.
Hybrid Solutions Before LangGraph
After the advent of Transformers and Large Language Models, hybrid solutions to building NLP application started to emerge post 2020.
KILT (Knowledge Intensive Language Tasks, 2020):
A benchmark for combining knowledge bases with language models. This focused more on evaluation.
Knowledge Graph and NLP Plugins (Neo4j NLP, 2021):
These are the tools for connecting language models with knowledge graphs, such as extracting entities or relationships. However, this tool was not streamlined for real time conversational applications or large language models.
LangChain(2022):
Provided modular tools for building language model applications, including Retrieval Augmented Generation (RAG). Until recently, this was the state of the art framework for integrating language model to domain-specific applications. However, this framework relied on unstructured or flat document-based retrieval, which limited its ability to handle complex, interconnected data. The lack of robust graph integration meant it could not fully leverage relationships and hierarchies within data, potentially restricting its effectiveness in scenarios requiring advanced semantic understanding or knowledge graph-based reasoning.
The Advent of LangGraph
The need for the ability to handle complex, interconnected data to leverage hierarchical relationships led to the advent of LangGraph.
Check out the official documentation for LangGraph: LangGraph Documentation
LangGraph takes inspiration from NetworkX, an open-source Python library as mentioned above. It is designed for building stateful, multi-actor applications with LLMs, making it ideal for creating multi-agent frameworks. Key features of LangGraph include cycles, branching, state persistence, and human-in-the-loop interactions, enabling fine-grained control and seamless integration with LangChain for complex workflows.
To demonstrate the advantages of LangGraph, here is an example that I worked on using LangChain to show how a traditional RAG workflow can be enhanced with stateful, graph-based reasoning.
Problem: Building a Conversational Agent with Context
Let’s say we want to build a conversational agent that can answer questions about a some document (I created example.txt that talks about history of computers for demo sake). The agent should:
Remember the context of the conversation.
Traverse interconnected information (e.g., relationships between historical events or figures).
Handle dynamic workflows (e.g., ask clarifying questions or branch based on user input).
With LangChain, this is challenging because the workflow is stateless and linear. Let’s see how we might implement this with LangChain:
For context, here is the example.txt that I have in my local drive:
The history of computers dates back to the early 19th century with the invention of mechanical devices like Charles Babbage's Analytical Engine. Although never fully built during his lifetime, Babbage's design laid the foundation for modern computing by introducing concepts such as programmable logic and memory.
In the mid-20th century, the first electronic computers emerged. The ENIAC (Electronic Numerical Integrator and Computer), completed in 1945, was one of the earliest general-purpose electronic computers. It was massive, occupying an entire room, and used vacuum tubes for processing. ENIAC was primarily used for military calculations, such as artillery trajectory tables.
The invention of the transistor in 1947 revolutionized computing. Transistors replaced vacuum tubes, making computers smaller, faster, and more energy-efficient. This led to the development of mainframe computers in the 1950s and 1960s, such as the IBM 700 series, which were used by businesses and governments for large-scale data processing.
The 1970s saw the rise of personal computers (PCs). The Altair 8800, released in 1975, is often considered the first commercially successful PC. It was followed by iconic machines like the Apple II and the IBM PC, which brought computing power to homes and small businesses.
The 1980s and 1990s were marked by rapid advancements in hardware and software. Graphical user interfaces (GUIs), pioneered by Xerox and popularized by Apple's Macintosh, made computers more accessible to non-technical users. The internet, which began as a government project, became widely available to the public in the 1990s, transforming how people communicate and access information.
Today, computers are ubiquitous, from smartphones and laptops to cloud-based systems and artificial intelligence. The evolution of computing continues to shape nearly every aspect of modern life.
The following is the LangChain code implementation (You would need to import your OpenAI API key to replicate this or you could use any other LLMs and would work just fine):
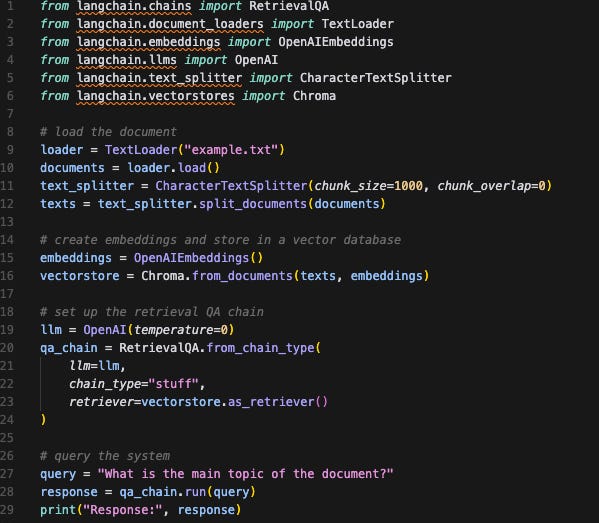
Here is the generated output:
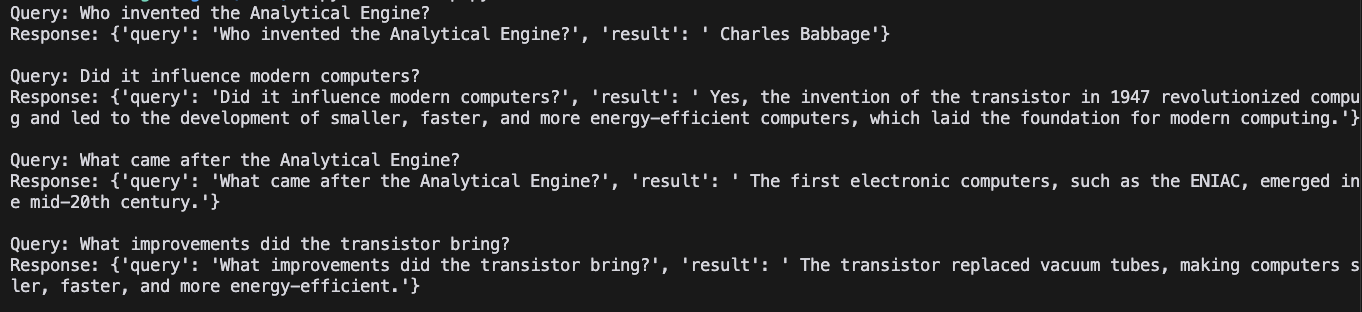
Limitations of LangChain
No Context Retention:
The agent doesn’t remember that “it” refers to ENIAC in the second query. As a result, it fails to provide a meaningful response.Flat Retrieval:
The agent retrieves information in isolation and doesn’t leverage relationships between concepts (e.g., how ENIAC led to the development of later computers).No Dynamic Workflows:
The agent can’t adjust its behavior based on previous interactions or ask clarifying questions.
Now let’s take a look at LangGraph. The following is the code implementation using LangGraph:
from typing import TypedDict, Annotated, Sequence
from typing_extensions import TypedDict
from langgraph.graph import Graph, StateGraph
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from dotenv import load_dotenv
import operator
# Load environment variables
load_dotenv()
# Load and prepare the document
loader = TextLoader("example.txt")
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
llm = OpenAI(temperature=0)
# Define the state structure
class State(TypedDict):
query: str
context: str
response: str
history: list[str]
# Define the nodes (functions that will process our data)
def retrieve_context(state: State) -> State:
"""Retrieve relevant context from the vector store."""
docs = retriever.get_relevant_documents(state["query"])
state["context"] = docs[0].page_content if docs else ""
return state
def generate_response(state: State) -> State:
"""Generate a response using the LLM."""
prompt = f"""
Based on the following context, answer the query.
Context: {state['context']}
Query: {state['query']}
"""
state["response"] = llm.invoke(prompt)
return state
def update_history(state: State) -> State:
"""Update conversation history."""
state["history"].append({
"query": state["query"],
"response": state["response"]
})
return state
# Create the graph
workflow = StateGraph(State)
# Add nodes
workflow.add_node("retrieve", retrieve_context)
workflow.add_node("generate", generate_response)
workflow.add_node("update_history", update_history)
# Add edges
workflow.add_edge("retrieve", "generate")
workflow.add_edge("generate", "update_history")
# Set entry and end points
workflow.set_entry_point("retrieve")
workflow.set_finish_point("update_history")
# Compile the graph
app = workflow.compile()
# Test queries
queries = [
"Who invented the Analytical Engine?",
"Did it influence modern computers?",
"What came after the Analytical Engine?",
"What improvements did the transistor bring?"
]
# Process queries
for query in queries:
# Initialize state for each query
state = State(
query=query,
context="",
response="",
history=[]
)
# Run the workflow
result = app.invoke(state)
# Print results
print(f"\nQuery: {query}")
print(f"Response: {result['response']}\n")
Here is the generated output:
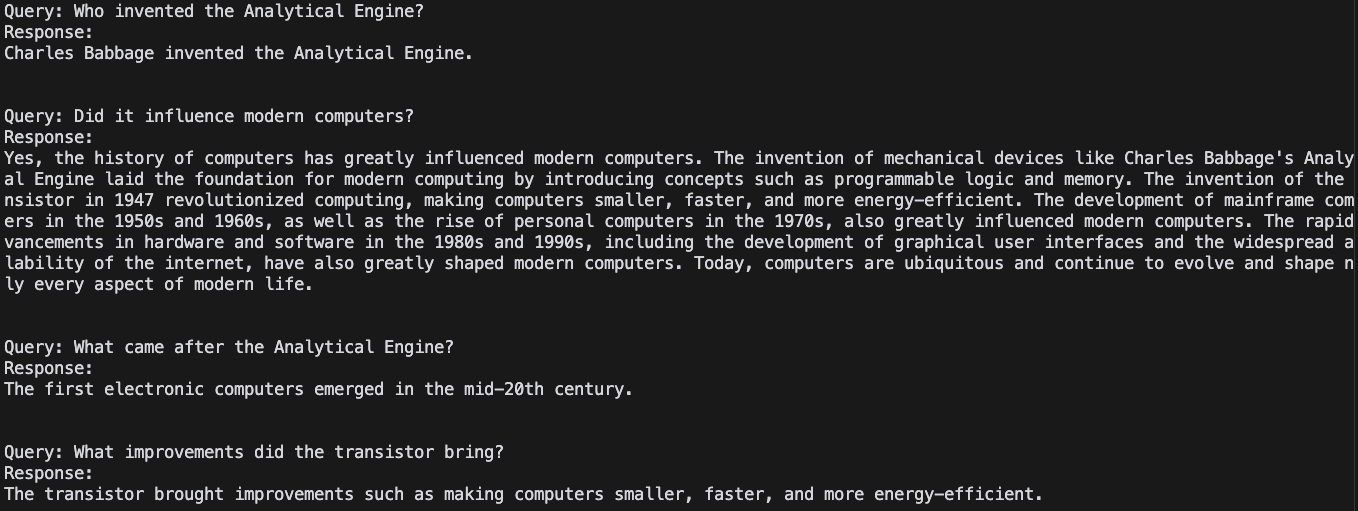
Finally, to showcase the advantages of LangGraph over langChain, let’s compare the responses between the two:
Comparison of Responses
Query 1: Who invented the Analytical Engine?
LangGraph Response:
Charles Babbage invented the Analytical Engine.
Analysis:
Direct and accurate response.LangChain Response:
Charles Babbage
Analysis:
Correct but lacks additional context or elaboration.
Query 2: Did it influence modern computers?
LangGraph Response:
Yes, the history of computers has greatly influenced modern computers. The invention of mechanical devices like Charles Babbage's Analytical Engine laid the foundation for modern computing by introducing concepts such as programmable logic and memory. The invention of the transistor in 1947 revolutionized computing, making computers smaller, faster, and more energy-efficient. The development of mainframe computers in the 1950s and 1960s, as well as the rise of personal computers in the 1970s, also greatly influenced modern computers. The rapid advancements in hardware and software in the 1980s and 1990s, including the development of graphical user interfaces and the widespread availability of the internet, have also greatly shaped modern computers. Today, computers are ubiquitous and continue to evolve and shape nearly every aspect of modern life.
Analysis:
LangGraph provides a detailed, coherent, and context-aware response. It not only confirms that the Analytical Engine influenced modern computers but also elaborates on how other developments (e.g., transistors, mainframes, personal computers) contributed to modern computing. This demonstrates LangGraph’s ability to retain context and provide comprehensive answers.LangChain Response:
Yes, the invention of the transistor in 1947 revolutionized computing and led to the development of smaller, faster, and more energy-efficient computers, which laid the foundation for modern computing.
Analysis:
While the response is correct, it focuses narrowly on the transistor and doesn’t explicitly connect the Analytical Engine to modern computers. It also lacks the depth and coherence of LangGraph’s response.
Query 3: What came after the Analytical Engine?
LangGraph Response:
The first electronic computers emerged in the mid-20th century.
Analysis:
LangGraph provides a direct and accurate response, clearly stating what followed the Analytical Engine.LangChain Response:
The first electronic computers, such as the ENIAC, emerged in the mid-20th century.
Analysis:
The response is correct but includes unnecessary details (e.g., "such as the ENIAC") that weren’t explicitly asked for.
Query 4: What improvements did the transistor bring?
LangGraph Response:
The transistor brought improvements such as making computers smaller, faster, and more energy-efficient.
Analysis:
LangGraph provides a clear and concise response, directly addressing the question.LangChain Response:
The transistor replaced vacuum tubes, making computers smaller, faster, and more energy-efficient.
Analysis:
The response is correct but includes extra information (e.g., "replaced vacuum tubes") that wasn’t explicitly asked for.
Key Differences and LangGraph’s Advantages
1. Context Retention
LangGraph:
LangGraph retains context across queries. For example, in the second query ("Did it influence modern computers?"), LangGraph understands that “it” refers to the Analytical Engine and provides a detailed response connecting it to modern computing.LangChain:
LangChain struggles with context retention. While it answers the question, it doesn’t explicitly connect the Analytical Engine to modern computers, focusing instead on the transistor.
2. Coherence and Depth
LangGraph:
LangGraph’s responses are coherent, detailed, and context-aware. For example, in the second query, it provides a comprehensive overview of how the Analytical Engine and subsequent developments influenced modern computing.LangChain:
LangChain’s responses are narrow and lack depth. For example, in the second query, it focuses narrowly on the transistor and doesn’t elaborate on the broader historical context.
3. Dynamic Workflows
LangGraph:
LangGraph supports stateful, multi-actor workflows, enabling it to handle complex, multi-turn conversations and dynamic decision-making.LangChain:
LangChain’s workflows are stateless and linear, limiting its ability to handle complex interactions.
4. Interconnected Reasoning
LangGraph:
LangGraph leverages graph-based reasoning to traverse relationships between concepts (e.g., connecting the Analytical Engine to modern computers).LangChain:
LangChain relies on flat retrieval, which limits its ability to reason about interconnected concepts.
Conclusion
LangGraph’s stateful, graph-based approach provides significant advantages over LangChain’s stateless, linear workflows. LangGraph excels in:
Context retention across queries.
Coherent and detailed responses that connect concepts.
Dynamic workflows for complex, multi-turn conversations.
Interconnected reasoning to traverse relationships between concepts.
These features make LangGraph a powerful tool for building advanced AI systems that require context-awareness, depth of understanding, and dynamic decision-making. In contrast, LangChain’s stateless design and flat retrieval limit its ability to handle complex, real-world scenarios.
Subscribe for More Content!
If you’re excited about the potential of graph-based AI and want to stay updated on the latest developments, subscribe to my channel or follow me for more content. Together, we’ll explore the cutting edge of AI and build systems that are smarter, more adaptive, and more powerful than ever before.
Let’s revolutionize AI with graphs!