


An AI Agent is an autonomous program designed to achieve specific goals by observing, reasoning, and acting on its environment using tools like data access, APIs, or external systems. Unlike standalone generative AI models (e.g., GPT), which generate responses based on input, agents actively plan, make decisions, and execute actions to accomplish tasks with minimal human intervention. They combine reasoning, logic, and external tools to extend beyond static AI capabilities, enabling dynamic problem-solving and task completion.

Core Components of AI Agents:
Model (LLMs):
Central decision-maker, often using multiple LLMs (large or small).
Capable of instruction-following, reasoning, and logic (e.g., ReAct, Chain of Thought, Tree of Thought).
Not pre-trained for specific agent configurations but can be fine-tuned with examples to improve tool usage and reasoning.
Tools:
Extend the agent’s capabilities by connecting it to the external world (e.g., APIs, databases, search engines).
Enable actions like data retrieval, computation, or interaction with other systems.
Orchestration Layer:
Manages the agent’s decision-making loop:
Observe: Gather information.
Reason: Analyze and plan actions.
Act: Use tools to execute decisions.
Continues until the goal is achieved or a stopping condition is met.
Complexity varies based on the agent’s task and environment.
Together, these components enable AI agents to autonomously process information, reason, and act effectively.
Agents vs. Models

This made sense to me except for the last row which I dug a little deeper. So basically, it highlights that models lack an inherent logic layer, meaning they do not have a structured reasoning or decision-making framework embedded within their architecture. Instead, users can guide the model by employing prompt engineering to introduce reasoning frameworks as needed which may or may not be robust and is manual. On the other hand, agents are equipped with a built-in cognitive architecture that includes reasoning frameworks like Chain of Thought, ReAct, or pre-built frameworks such as LangChain. LangChain, for instance, provides preconfigured reasoning frameworks and facilitates tool orchestration aligned with session history.
Popular Reasoning Techniques for LLMs and Agents:
ReAct (Reason + Act):
A framework where the model reasons through a problem step-by-step and acts by using tools or external resources.
Combines reasoning (e.g., "I need to find X") with action (e.g., "I will search for X").
Works with or without in-context examples.
Ideal for tasks requiring both reasoning and tool usage.
Chain of Thought (CoT):
Encourages models to break down problems into intermediate reasoning steps.
Sub-techniques include:
Self-Consistency: Aggregates multiple reasoning paths for more robust answers.
Active-Prompt: Dynamically selects examples to improve reasoning.
Multimodal CoT: Extends reasoning to multimodal inputs (e.g., text + images).
Strengths: Improves accuracy for complex, step-by-step problems.
Weaknesses: May require careful prompt design and can be computationally expensive.
Tree of Thought (ToT):
Generalizes CoT by exploring multiple reasoning paths (like branches of a tree).
Well-suited for tasks requiring exploration or strategic lookahead (e.g., planning, game-solving).
Allows models to evaluate and backtrack across different thought chains.
Strengths: Enables more flexible and creative problem-solving.
Weaknesses: Can be resource-intensive and complex to implement.
These frameworks enhance LLMs' reasoning and decision-making capabilities, with each suited to specific types of tasks. Agents often integrate these techniques into their cognitive architecture for autonomous, structured problem-solving.
So how can we empower our models to have real-time, context-aware interaction with external systems?
Extensions

Extensions standardize how agents interact with APIs, enabling seamless API execution regardless of implementation. They guide agents on API usage through examples, detailing required arguments and parameters for successful calls.
Key Features:
Independence: Extensions can be created separately but must be included in the agent's configuration.
Dynamic Selection: At runtime, the agent uses models and examples to determine the most suitable extension for addressing user queries.
Functions

Functions are reusable code components, similar to those in software engineering, designed to automate repetitive tasks. Models can utilize predefined functions, deciding when to use them and what arguments are needed based on specifications.Key Differences:
Functions output the function and its arguments but do not make live API calls.
They are executed on the client side, while extensions run on the agent's side.
Why Use Functions?
Functions provide developers with precise control over data flow and execution while leveraging the model for input generation. Key benefits include:Security: Keeps sensitive information secure.
Task Management: Enables long-running tasks to execute in the background while the agent continues other operations.
System Flexibility: Allows execution on specific systems (e.g., secure servers).
For example, if an agent suggests a weather-check function, your code would handle the API call and fetch the data, maintaining execution control.
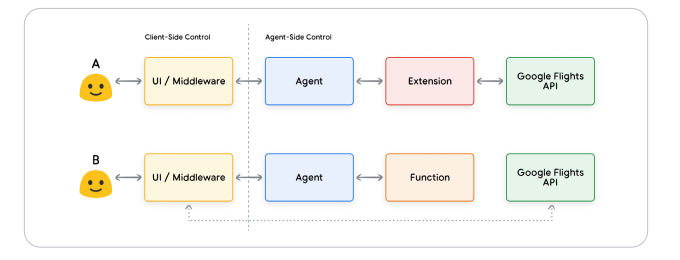
I was actually confused on how the extentions and fucntions really differ. Here is the key difference which made a lot of sense:
Functions: Handled by you (the developer) on the client-side. They’re great for specific tasks, keeping secrets safe, and running things in the background.
Extensions: Built into the agent and run on the agent-side. They make the agent smarter by adding built-in capabilities like reasoning, session management, and tool use.
Data Stores

Data Stores enhance pre-trained LLMs by providing access to dynamic, up-to-date information, ensuring responses remain factual and relevant. They allow developers to supply additional data in its original format, avoiding the need for time-consuming transformations, retraining, or fine-tuning.
Key Features:
Vector Embeddings: Incoming documents are converted into vector embeddings that agents use to extract supplemental information.
Runtime Access: Implemented as a vector database, accessible by the agent during runtime.
Use Case: Widely used in Retrieval-Augmented Generation (RAG) applications to extend a model's knowledge beyond its foundational training data, supporting diverse data formats.
Effective Use of Models: Choosing the Right Tools
Models need to select appropriate tools to generate accurate outputs, especially in production-scale scenarios. While foundational training helps, real-world applications often require domain-specific knowledge, akin to mastering a cuisine beyond basic cooking skills.
Approaches for Accessing Specific Knowledge:
In-Context Learning:
Provides a generalized model with prompts, tools, and few-shot examples during inference to learn "on the fly."
Example: The ReAct framework for natural language tasks.
Retrieval-Based In-Context Learning:
Dynamically retrieves relevant information, tools, and examples from external memory to populate model prompts.
Example: Vertex AI’s "Example Store" or RAG-based architectures.
Fine-Tuning Based Learning:
Pre-trains the model with a dataset of specific examples, enabling it to understand how to use tools before any user queries.
Finally, here is an example of production level architecture uising Google’s services that can be orchestracted from the concepts just discussed!
