

ML: Clustering
Clustering helps organize data into meaningful groups by identifying patterns and structures within the data.

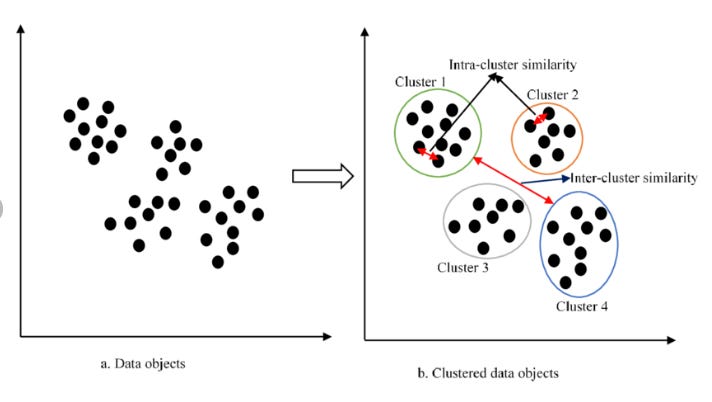
Clustering is a type of unsupervised learning technique used to group a set of objects or data points into clusters, where objects within the same cluster are more similar to each other than to those in other clusters. The goal is to identify inherent patterns or structures in the data without prior knowledge of the group labels.
Key Aspects of Clustering
Similarity: Clustering relies on measures of similarity or distance between data points to form groups. Common metrics include Euclidean distance, Manhattan distance, and cosine similarity.
Cluster Formation: The process involves partitioning the data into distinct clusters where each cluster contains data points that share common characteristics.
Unsupervised: Clustering does not require labeled data; it discovers patterns and structures in the dataset on its own.
Applications: Clustering is used in various fields such as market segmentation, image processing, anomaly detection, and bioinformatics.
Types of Clustering
Partitioning Methods: Divide the dataset into a predefined number of clusters (e.g., K-means).
Hierarchical Methods: Build a hierarchy of clusters (e.g., Agglomerative or Divisive clustering).
Density-Based Methods: Group data based on the density of data points (e.g., DBSCAN).
Model-Based Methods: Assume a model for the data and find clusters that fit the model (e.g., Gaussian Mixture Models).