

PySpark: Python’s Gateway to Big Data Brilliance
A Deep Dive into Apache Spark’s Python API, with Code and Real-World Insights

What is Apache Spark?
Apache Spark is an open-source distributed computing framework built for speed and scalability. It was developed at UC Berkeley in 2009 and has become a key project under the Apache Software Foundation. Spark is designed to handle massive datasets by distributing the workload across multiple machines. Unlike older tools such as Hadoop MapReduce, which rely heavily on disk storage, Spark processes data in memory, significantly reducing processing times—IBM estimates it can be 10 to 100 times faster. It serves as a unified engine that supports batch processing, real-time streaming, machine learning, and graph analytics within a single platform.
Why is it needed?
Modern data is growing rapidly in size, speed, and complexity, making single-machine tools like pandas insufficient. Spark can scale from a personal laptop to a full cloud-based cluster, integrates seamlessly with storage systems like S3 and HDFS, and provides APIs in Python, Scala, and other languages. It has become an essential tool for organizations of all sizes that rely on data to drive decisions.
What is Pyspark?
PySpark is the Python API for Apache Spark, bringing the power of distributed computing to the Python ecosystem. If you're already familiar with Python tools like pandas, NumPy, or Jupyter notebooks, using PySpark will feel intuitive. It simplifies the process of working with clusters by handling the infrastructure behind the scenes, allowing you to focus on writing data logic.
With PySpark, you gain access to Spark's full capabilities, including Spark SQL for querying, MLlib for machine learning, Structured Streaming for handling real-time data, and GraphX for graph processing—all using Python.
A key comparison is with pandas, a staple for data analysis. The table below outlines their differences:

As noted above, Pandas is ideal for datasets fitting in memory, offering rich functions for analysis. PySpark, however, excels with large datasets, scaling from local development to production clusters, making it a bridge for data professionals upgrading from pandas.
Real-World Adoption and Community Support
PySpark’s adoption is evident in industries like finance (FINRA), real estate (Zillow), and technology (Yelp), as per AWS’s use case list (AWS: What is Apache Spark?). Its community, with over 2,000 contributors and used by 80% of Fortune 500 companies, ensures continuous development.
Code implementation
To demonstrate the power of PySpark, I recently started to work on a Kaggle dataset titled Amazon Reviews. This section is not a comprehensive analysis but rather a demonstration of how PySpark can be used to handle and explore large-scale data.
Environment Setup
Getting PySpark set up wasn’t completely smooth.
When I tried installing PySpark, I encountered the following issue:
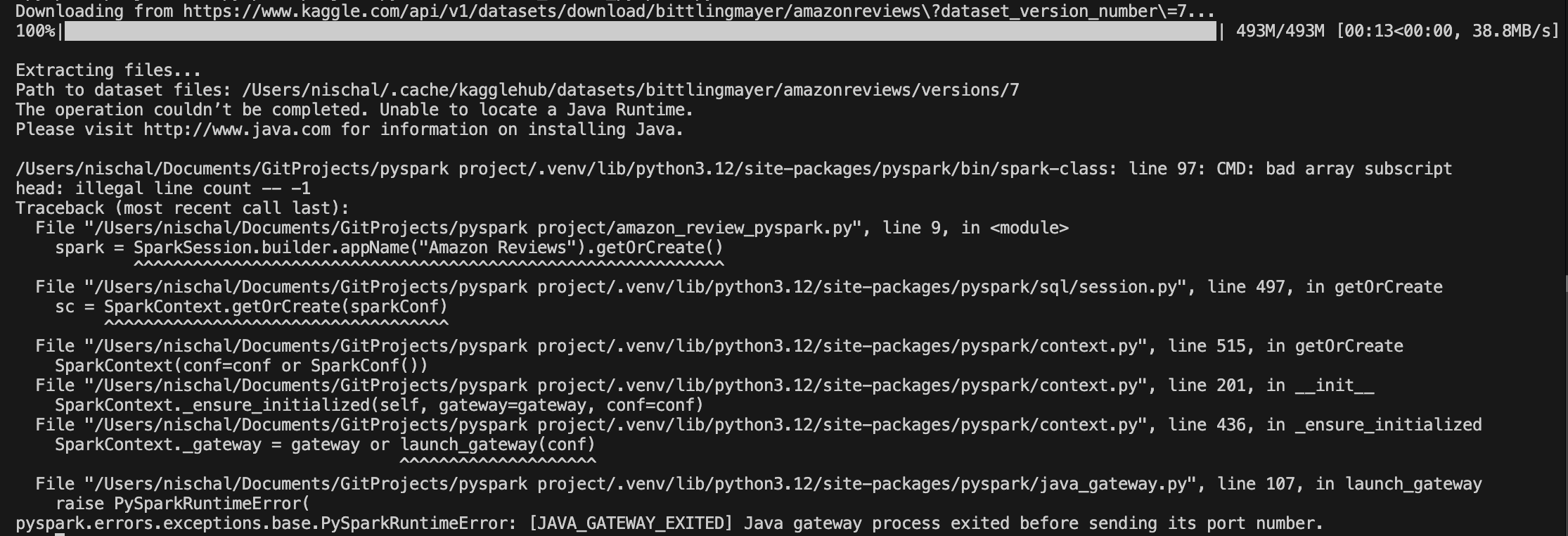
Turns out, PySpark runs on top of the JVM (Java Virtual Machine) and thus requires Java to be correctly installed and linked in the environment.
brew install openjdk@11Then, I had to set the JAVA_HOME environment variable manually since the Java installation path wasn’t where PySpark expected it to be. I located the correct path and added this to my shell config:
export JAVA_HOME="/opt/homebrew/opt/openjdk@11"Finally, here is the output generated from the training set.

Exploratory Data Analysis
There is essentially no shortcut when it comes to understanding the size of a large dataset in Spark — any operation that scans the full data will trigger computation across the cluster.
For example, using:
df.count()launches a Spark job that scans all the partitions to return the total number of rows.
In this case, the dataset contains 3.6 million rows, with a balanced binary label:
50% of the reviews are labeled as A, corresponding to low ratings (1 or 2 stars),
The other 50% are labeled as B, representing high ratings (4 or 5 stars).
Another thing worth noting is how seamlessly a PySpark DataFrame can be converted to a Pandas DataFrame using:
df_pandas = df.toPandas()However, while this can be convenient for small samples or prototyping, working with millions of rows in Pandas can lead to memory bottlenecks. This limitation is one of the key reasons PySpark exists — it enables scalable data processing across distributed clusters, which is essential when dealing with large-scale datasets like this one.
That said, sampling smaller subsets for local inspection can be helpful:
sample_df = df.sample(fraction=0.01).toPandas()This lets you explore data quickly in Pandas without overloading your system.
df.select('review').show(10)This selects the column with n number of rows.
Machine Learning with PySpark: Logistic Regression
After cleaning and transforming the text data (tokenization, stopword removal, feature hashing), I built a logistic regression model using PySpark’s MLlib.
Here’s how pipeline can be built:
from pyspark.ml.feature import Tokenizer, StopWordsRemover, HashingTF
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
tokenizer = Tokenizer(inputCol="review", outputCol="words")
remover = StopWordsRemover(inputCol="words", outputCol="filtered")
hashingTF = HashingTF(inputCol="filtered", outputCol="features", numFeatures=10000)
lr = LogisticRegression(featuresCol="features", labelCol="label")
pipeline = Pipeline(stages=[tokenizer, remover, hashingTF, lr])
model = pipeline.fit(df)
Once trained, you can evaluate the model or make predictions:
predictions = model.transform(df)
predictions.select("review", "label", "prediction").show(5)Summary
PySpark is a powerhouse for handling big data. It handles everything from preprocessing millions of text reviews to building scalable machine learning models. While Pandas is great for quick exploration and prototyping, Spark truly shines when you need scale, speed, and distributed computing.
If you’re dealing with text-heavy, high-volume datasets, learning PySpark is 100% worth the effort.