

Web Scraping with Selenium: Extracting Data from Complex Websites
Guide to Scraping Job Postings

Selenium is an open source framework which provides a suite of tools primarily used for automating web browsers.
Components of Selenium:
Selenium Web Driver - A core component that allow you to interact directly with the web browsers. Provides APIs for browser automation in multiple programming languages. Automates user actions like clicks, filling forms, navigating pages and validating content.
Selenium Integrated Development Environment - A simple browser extension for Chrome and Firefox which allows users to record and playback user interactions with a web application for a quick test creation.
Selenium Grid - Used for parallel test execution on multiple browsers and systems. This can help distribute test execution across different environments to save time. This is particularly useful for large scale testing setup.
Selenium is widely used for automated testing, CI/CD pipelines, and browser automation. Although its primary purpose is not web scraping, it is often utilized for this task despite potential ethical considerations. As a data scientist, understanding the web scraping process is crucial, as the data collected can be leveraged for downstream tasks such as model training, Retrieval-Augmented Generation (RAG) for LLMs, or other applications.
For instance, in the following demo of scraping a job website, extracting job descriptions could be used to evaluate resumes by leveraging an LLM to determine if they align well with the requirements of various job postings.
To effectively scrape complex websites using Selenium, it’s essential to understand several key components of the framework.
Today, I’ll demonstrate how to use Selenium to scrape a more complex website, such as Indeed, for job postings. The extracted job data will then be saved locally in a CSV format.
At the time of scraping, the Indeed job board looks as follows:
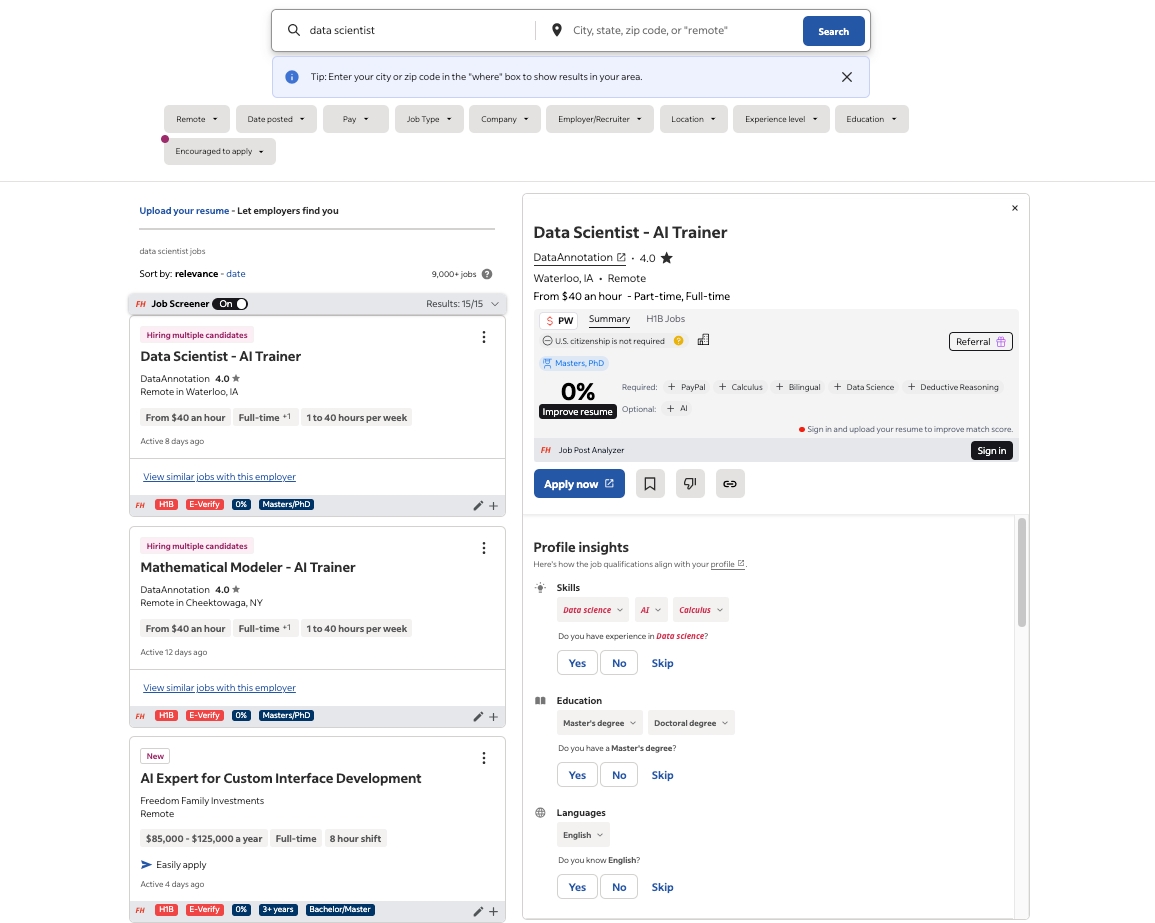
Below is a breakdown of the code, along with an explanation of the critical parts and objects that are fundamental for implementing this project:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import (NoSuchElementException, TimeoutException,
StaleElementReferenceException,
ElementClickInterceptedException)
import csv
import time
import randomwebdriver: Starts and configures the web browser
Service: Manages the Chrome WebDriver service
By: Specifies location strategies for finding the web elements (e.g. XPATH)
WebDriverWait: Provides explicit wait times for elements to load and conditions to be met.
expected_conditions: A set of pre-defined conditions for waiting (e.g waiting until element visibility)
I have included common exceptions as well in order to catch those just in case. More exceptions can be found on the official documentation.
Next, define the executable. To get the executable for Chrome, ensure you download it from the official website and verify that the version matches the version of Chrome you are using. After downloading, the executable should be placed in the same folder as the script so that Selenium can reference it.
Here is how to configure Chrome WebDriver:
service = Service(executable_path='path_to_downloaded_executable_mentioned_above')
options = webdriver.ChromeOptions()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--start-maximized")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=service, options=options)
wait = WebDriverWait(driver, 15)Service: path to the Chrome WebDriver Executable
I found these options super useful. Most websites are now advanced enough to detect bot activity. The following command is useful to make it hard for the website to flag the bot.
--disable-blink-features=AutomationControlled: Reduces detection as a bot.
Since my computer had fairly large CPU/memory at the time of running this, I added additional options to handle automated browsing more efficiently (these are optional features):
--start-maximized: Launches the browser maximized.--disable-gpu,--no-sandbox,--disable-dev-shm-usage: Stability options for headless browsing or environments with limited resources.
WebDriverWait(driver, 15) makes sure to specify explicit wait to handle dynamic elements (e.g., waiting up to 15 seconds for elements to load).
Besides these, there are few helper functions for bots to explicitly make sure they act like humans!
time.sleep(random.uniform(min, max))This ensures human like delays while browsing, where I set the min and the max to be 1 and 3 respectively.
WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((by, value))
)As mentioned above, this makes sure that the browsers wait but with added conditional, which is until the elements are present while handling timeouts.
For certain clicks, I implemented JavaScript to do click fall backs in case of regular click. This is needed for overlapping elements.
driver.execute_script("arguments[0].click();", element)Next is the main scraper method, which contains the core logic for processing individual job cards. This method identifies the job title and attempts to click on the job card using both regular and JavaScript methods. Finally, it retrieves the job description after successfully clicking. This was the most challenging part to implement because the job title and job description remain static, requiring precise handling to ensure accurate extraction.
def process_job_card(index, total):
"""Process a single job card with enhanced error handling"""
try:
# Refresh job cards list
cards = refresh_job_cards()
if not cards or index >= len(cards):
print(f"No card found at index {index}")
return None
card = cards[index]
# Scroll to card
driver.execute_script(
"arguments[0].scrollIntoView({block: 'center', behavior: 'smooth'});",
card
)
human_delay(2, 3)
# Get job title
title_element = safe_find_element(
By.XPATH,
".//h2[contains(@class, 'jobTitle')]",
timeout=10,
parent=card
)
if not title_element:
print(f"Could not find title for job {index + 1}")
return None
job_title = title_element.text.strip()
print(f"Processing job {index + 1}/{total}: {job_title}")
# Click the card
try:
wait.until(EC.element_to_be_clickable((By.XPATH, f"(//div[contains(@class, 'cardOutline')])[{index + 1}]")))
driver.execute_script("arguments[0].click();", card)
except Exception as e:
print(f"Click failed for job {index + 1}: {str(e)}")
return None
# Wait for and get description
description_element = safe_find_element(
By.ID,
"jobDescriptionText",
timeout=15
)
if not description_element:
print(f"Could not find description for job {index + 1}")
return None
# Return to job list
try:
back_link = safe_find_element(
By.CSS_SELECTOR,
"a[aria-label='Back to search results']",
timeout=5
)
if back_link:
driver.execute_script("arguments[0].click();", back_link)
human_delay(2, 3)
except Exception:
# If back link fails, try refreshing the page
driver.refresh()
human_delay(3, 5)
return {
'title': job_title,
'description': description_element.text.strip()
}
except Exception as e:
print(f"Error processing job {index + 1}: {str(e)}")
# Try to recover by refreshing the page
driver.refresh()
human_delay(3, 5)
return NoneHere is how the scrolling and loading is handled:
for _ in range(4): driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") human_delay(2, 3) driver.execute_script("window.scrollTo(0, 0);") human_delay(1, 2)This makes sure that job to the bottom of the page multiple times, ensuring additional job cards load dynamically.
Finally, this is how it is finding each job posting box:
selectors = [
"//div[contains(@class, 'cardOutline')]",
"//div[contains(@class, 'job_seen_beacon')]",
"//div[contains(@class, 'tapItem')]"
]
for selector in selectors:
try:
cards = driver.find_elements(By.XPATH, selector)
if cards:
job_cards = cards
print(f"Found {len(cards)} jobs using selector: {selector}")
break
except Exception:
continue
Uses multiple XPath selectors to locate job cards and stops once valid cards are found.
Practical Advice:
Inspect Elementfeature of Google Chrome is pretty useful to figure out Id, class name and css selectors!
With all that, here is the final result of how jobs are scraped!
Found 15 jobs
Processing job 1/15: Data Scientist - AI Trainer at DataAnnotation
Successfully scraped job 1
Processing job 2/15: Automation Engineer - AI Trainer at DataAnnotation
Successfully scraped job 2
Processing job 3/15: Data Scientist at The University of Pittsburgh
Successfully scraped job 3
Processing job 4/15: Data Scientist at The University of Pittsburgh
Successfully scraped job 4
Processing job 5/15: Data Scientist, Operations Research at Delta Airlines
Successfully scraped job 5
Processing job 6/15: Data Scientist at Tagup
Successfully scraped job 6
Processing job 7/15: Data Scientist at Tagup
Successfully scraped job 7
Processing job 8/15: Data Scientist at Microsoft
Successfully scraped job 8
Processing job 9/15: Data Scientist at Booz Allen
Successfully scraped job 9
Processing job 10/15: Data Scientist II - Hybrid at Radian
Successfully scraped job 10
Processing job 11/15: Data Scientist - Hybrid at Alliant Credit Union
Successfully scraped job 11
Processing job 12/15: Data Scientist, Operations Research at Delta Airlines
Successfully scraped job 12
Processing job 13/15: Data Scientist, Operations Research at Delta Airlines
Successfully scraped job 13
Processing job 14/15: Data Scientist at Apple
Successfully scraped job 14
Processing job 15/15: Associate Data Scientist at The University of Chicago
Successfully scraped 15 jobs
Note: I noticed that some of the postings scraped are exact duplicates. I believe this is happening because the website dynamically loads job listings, and certain entries might be reloaded or duplicated during multiple scrolls or page refreshes. This behavior is common in sites with infinite scrolling or AJAX-based content loading.
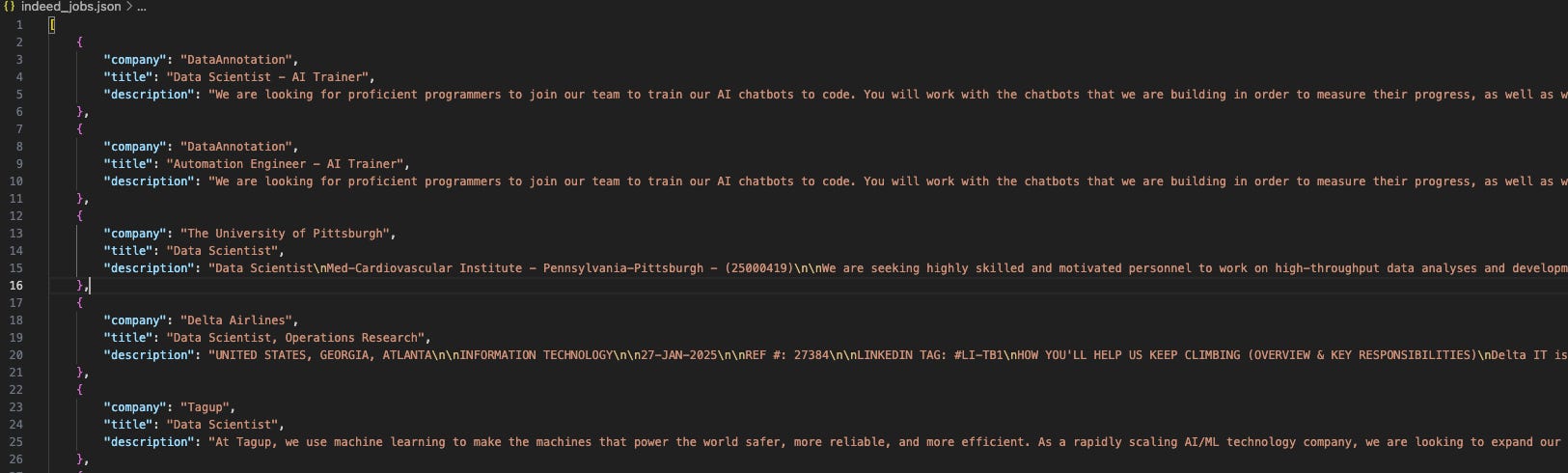
Example JSON output:
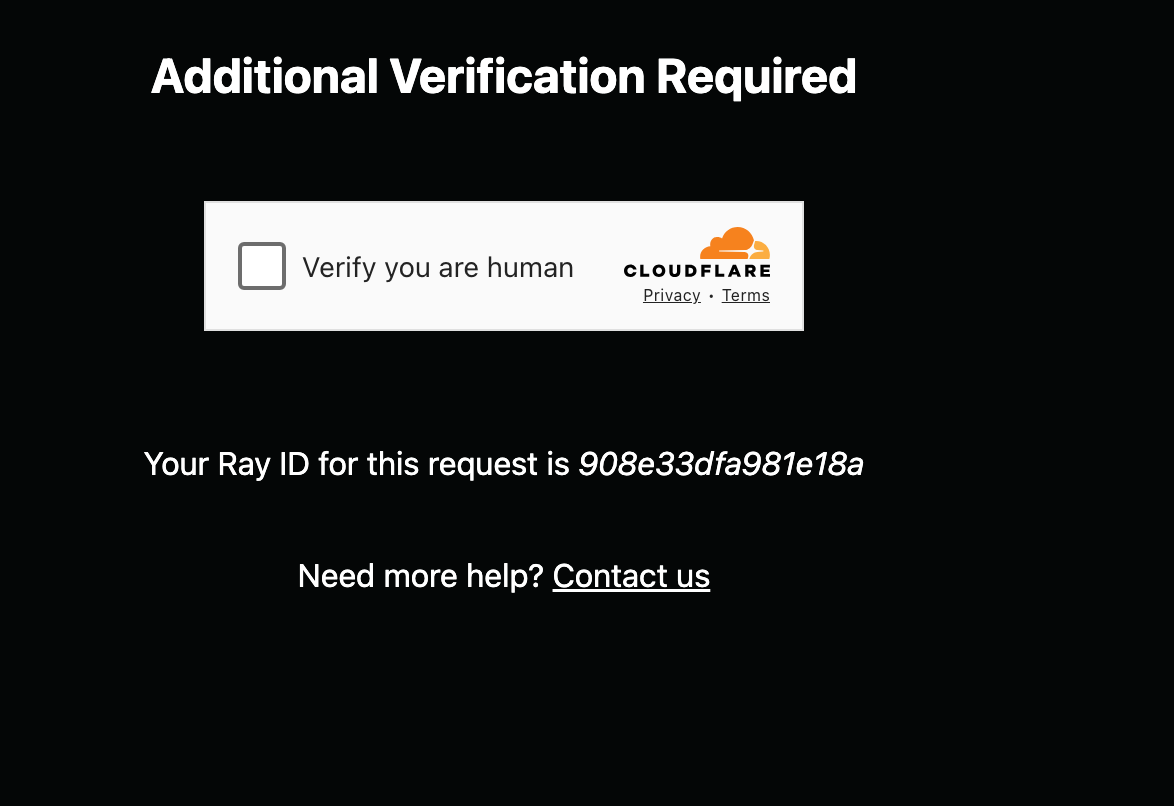
Finally, another challenge I faced was that Indeed’s website is highly protected. I frequently encountered verification prompts during sequential scraping attempts. I tried implementing retries, but it didn’t resolve the issue. Websites like Indeed continuously improves its security protocols and utilizes Cloudflare.
Here is an example after I tried scraping a few hours later:
Processing job 1/15: Data Scientist - AI Trainer at DataAnnotation
Successfully scraped job 1
Attempt 1 failed for job 2: Message:
Processing job 2/15: Mathematical Modeler - AI Trainer at DataAnnotation
Successfully scraped job 2
Processing job 3/15: Data Scientist at COD HEALTH CARE LLC
Successfully scraped job 3
Attempt 1 failed for job 4: Message:
Attempt 2 failed for job 4: Message:
Attempt 3 failed for job 4: Message:
Failed to process job 4 after 3 attempts
Attempt 1 failed for job 5: Message:
Attempt 2 failed for job 5: Message:
Attempt 3 failed for job 5: Message:
Failed to process job 5 after 3 attempts
Attempt 1 failed for job 6: Message:
Attempt 2 failed for job 6: Message:
Attempt 3 failed for job 6: Message:
Failed to process job 6 after 3 attempts
Attempt 1 failed for job 7: Message:
Attempt 2 failed for job 7: Message:
Attempt 3 failed for job 7: Message:
Failed to process job 7 after 3 attempts
Attempt 1 failed for job 8: Message:
Attempt 2 failed for job 8: Message:
Attempt 3 failed for job 8: Message:
Failed to process job 8 after 3 attempts
Attempt 1 failed for job 9: Message:
Attempt 2 failed for job 9: Message:
Attempt 3 failed for job 9: Message:
Failed to process job 9 after 3 attempts
Attempt 1 failed for job 10: Message:
To work around this, I used an undetected bot package for Selenium with rotating proxies. While it sometimes worked, it often failed. Maintaining the script is crucial to ensure consistent scraping on websites with this level of protection!
Full Code
https://github.com/Nischal1011/data_projects
Super Insightful!